
Mood Detection Using openCV and Keras
- Aniket Katakdhond
- Aug 26, 2020
- 5 min read

Updated: Dec 4, 2020
Hello guys, this is Aniket. This is my first blog.
At first, what content to share with you ,was very head-aching question. Why not go through my Deep learning journey ( as of now, still i am a learner, neither a pro nor a noob ) and all the projects I have made and share with you guys?" Hope you like my Blog, and motivate me to write more content.
Coming to the main part, I will guide you step by step, to build your First Mood Detection Project in Python using Keras and openCV . Before Starting Let me clear that you need to have Basic Understanding of Python, How to import Images from .csv files using Pandas and also basic understanding of Keras and OpenCV python Library. But if you don't know any of these, don't worry, Down here are some useful links:-
Without any further delay, let's get started.
First of all, you need to download this training Dataset in your computer, which is in .csv format. The file contains, 3 columns (emotion, Usage and pixels) and near about 34000 training and test data set, Comprising of 7 distinct emotions,namely, angry, disgust, fear, happy, neutral, sad and surprise.
Our First task is to convert the string values of images, given in csv files as pixels, to images of dimensions ( 48 ,48 ,3 ) as per their emotion label and Usage in different files.
Firstly import the required libraries.. (make sure that these libraries are installed in your system)
import pandas as pd
import numpy as np
import cv2Then import the csv file and get images.
Before doing this, create 2 folders in your project folder, train and test.
Within each, create 7 folders, namely emotion labels.
k=0
data=pd.read_csv(r'Enter csv file path',delimiter=',')
for index,row in data.iterrows():
pixels=np.asarray(list(row[' pixels'].split(' ')),dtype=np.uint8)
img=pixels.reshape((48,48))
usage=data[' Usage'][k]
emotion=data['emotion'][k]
if(usage=="Training"):
if(emotion==0):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\angry\angry"+str(k)+".jpg",img)
if(emotion==1):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\disgust\disgust"+str(k)+".jpg",img)
if(emotion==2):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\fear\fear"+str(k)+".jpg",img)
if(emotion==3):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\happy\happy"+str(k)+".jpg",img)
if(emotion==4):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\sad\sad"+str(k)+".jpg",img)
if(emotion==5):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\surprise\surprise"+str(k)+".jpg",img)
if(emotion==6):
cv2.imwrite(r"C:\Users\systemname\projectfilename\train\neutral\neutral"+str(k)+".jpg",img)
else:
if(emotion==0):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\angry\angry"+str(k)+".jpg",img)
if(emotion==1):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\disgust\disgust"+str(k)+".jpg",img)
if(emotion==2):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\fear\fear"+str(k)+".jpg",img)
if(emotion==3):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\happy\happy"+str(k)+".jpg",img)
if(emotion==4):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\sad\sad"+str(k)+".jpg",img)
if(emotion==5):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\surprise\surprise"+str(k)+".jpg",img)
if(emotion==6):
cv2.imwrite(r"C:\Users\systemname\projectfilename\test\neutral\neutral"+str(k)+".jpg",img)
k=k+1
print("Data Saved")
#0=angry,1=disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral

The above code snippet, reads the Usage and emotion of each row, and stores the image in respective location. After running this, you should be able to see black and white images in folders, each of (48,48,3) Dimensions. Name this above python file as excel_dataset.py
Now we will create a python file, EmoDet.py, which will get access to your system camera, and capture the frames, and highlight your mood.
import cv2
import matplotlib.pyplot as plt
import numpy as np
import classify_image
from PIL import Image
import warnings
from keras.preprocessing import image
cap=cv2.VideoCapture(0) # access system camera
def det_face(img):
face_img=img.copy()
face_cascade=cv2.CascadeClassifier(r'path for ha')
face_rects=face_cascade.detectMultiScale(face_img)
for(x,y,w,h) in face_rects:
cv2.rectangle(face_img,(x,y),(x+w,y+h),(0,255,0),5)
i=classify_image.show(img,face_rects)
test_img=image.img_to_array(i)
test_img=np.expand_dims(test_img,axis=0)
test_img=test_img/255
print(classify_image.imgprocess(test_img))
return face_img
while True:
ret,frame=cap.read()
frame=det_face(frame)
cv2.imshow('Video Face Detect',frame)
if cv2.waitKey(1)==27:
break
cv2.release()
cv2.destroyAllWindows()While passing the frame to classify_image file, we need only the face part of image. This we have achieved by using haarcascade_frontalface_alt. If you are new to haarcascades, find info here.
Also, Download harcasscade file here, and store in the same file as project.
Now we come to the main part, where we will train our model on training and test data.
import cv2
import pandas as pd
import numpy as np
from PIL import Image
import warnings
from keras.models import model_from_json
input_shape=(48,48,3)
from keras.preprocessing.image import ImageDataGenerator
image_gen=ImageDataGenerator(rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
rescale=1/255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
#setting up training model
from keras.models import Sequential
from keras.layers import Activation,Dropout,Flatten,Conv2D,MaxPooling2D,Dense
model=Sequential()
model.add(Conv2D(filters=32,kernel_size=(3,3),input_shape=(48,48,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,kernel_size=(3,3),input_shape=(48,48,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,kernel_size=(3,3),input_shape=(48,48,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(128,activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(7,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
print(model.summary())
#prints summary of the model, displays number of layers, initially thier in nothing fitted in the model,so shows null
batch_size=15
train_image_gen=image_gen.flow_from_directory(r"C:/Users/systemname/projectname/train",target_size=input_shape[:2],batch_size=batch_size,class_mode='categorical')
test_image_gen=image_gen.flow_from_directory(r"C:/Users/systemname/projectname/test",target_size=input_shape[:2],batch_size=batch_size,class_mode='categorical')
print(train_image_gen.class_indices)
results=model.fit(train_image_gen,epochs=15,steps_per_epoch=1000,validation_data=test_image_gen,validation_steps=12)
warnings.filterwarnings('ignore')
print(results.history['accuracy'])
# Saving the model and weights
model_json = model.to_json()
with open("model1.json", "w") as json_file:
json_file.write(model_json)
model.save_weights("model1.h5")
print("Saved model to disk")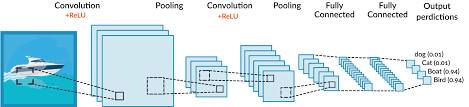
(Source: www.MissingLink.ai.com)
Looks a lot confusing! Don't worry we will go step by step. ( click on the layer name to get more information )
The ImageDataGenerator is Keras library, essentially used for augmentation of images. Using this one can rotate the images, transform the height width, rescale pixel values,and much more. Augmentation is neccessary so as to improve the performance of model on datasets. For understanding why augmentation is neccessary click here.
A Sequential model is appropriate for a plain stack of layers where each layer has exactly one input tensor and one output tensor.
A Conv2D is convolution layer, which is used for generating filters (which are actually kernels ). We input the number of filters to be extracted and the kernel size of each filter.
A MaxPooling layer is used to select the maximum element from a feature map covered by the filter. Thus, the output after max-pooling layer would be a feature map containing the most prominent features of the previous feature map. It is used to speed up the training time of model.
A Flatten Layer transforms a two-dimensional matrix of features into a vector that can be fed into a fully connected neural network classifier, in our case, to the Dense layer for further classification.
The Dropout layer drops out units in the neural network. It is a simple manner of preventing overfitting of dataset. In our example, 0.4 means, out of every 10 units, 4 units will be dropped.
Finally, the Activation functions are used to classify whether it should be activated or not (value either 0 or 1). We will Discuss activation functions in more detail another blog.
Finally the dataset is fitted in the model using model.fit . Verify how well your model is predicting on test set.
Now once the training is done, we need to save the model and weights of this Convolution Neural Network, in the same above project file, so that we don't need to train the model again and again.
This is done using model_from_json library in keras. The file is stored as, one file in .h5 extension and other in .json .
Name the above file as Trained_model.py .
Remember, above in EmoDet.py file we imported classify_image file and used it to pass the the face image! Now we will code this classify_image.py .
import cv
from keras.models import model_from_json
from keras.preprocessing import image
def imgprocess(img):
json_file=open('model1.json','r')
loaded_model_json=json_file.read()
json_file.close()
loaded_model=model_from_json(loaded_model_json)
loaded_model.load_weights("model1.h5")
return loaded_model.predict_classes(img)
def show(img,face_rects):
for(x,y,w,h) in face_rects:
i=img[y:y+h,x:x+w]
i=cv2.resize(i,(48,48), interpolation = cv2.INTER_AREA)
return i
From EmoDet, we pass the frame and face detected rectangle coordinates. The show() function returns back the face part of the image, resized to (48,48) dimensions.
After that, in the EmoDet function, the cropped face image is converted to array, dimensions are expanded ( so as to convert (48,48,3) to (1,48,48,3)). Then, as we had scaled the pixel values between 0 and 1 in training model, we need to scale image by dividing by 255. Finally the pass the image in imgprocess() kk function in classify_img.py file.
For Every frame, we get values from 0-6, as per the emotion you display on camera, on the terminal.
Further, you can even Text the emotion on the image itself, to make it more attractive.
To make it more interesting, play a song in background as per the mood.
To be honest, I personally think this project can be used for detecting mood of driver and accident prevention, Import social media posts and study the depression rate in society.

Hope you enjoyed doing this project.
And please do like and comment what i should do next, any projects involving neural networks, computer vision...
Thank you.
(<=Source: www.towardsdatascience.com)


Comments